
We create a 5-rule parser to efficiently and accurately parse affirmative present tense sentences in Japanese. With just 5 rules you can understand Japanese grammar deeply.
Deconstructing Japanese
Linguistics is often unnecessarily complicated. “Why state concisely with one term when there are 300 different varieties for these intimates and particulars?!” Simplicity speaks volumes and good teachers teach simple concepts that help unify greater features easily.
To that end, let’s see if we can produce Japanese with an EBNF grammar.
For this we will be using an excellent functional library for clojure called Instaparse.
You can see a live demo of Instaparse online with this grammar here.
Update: 2020-1-8: A fully recursive parser can be found here http://instaparse-live.matt.is/#/-Ly5y7xvJoDkHhIs0UKD/v1
What’s an EBNF grammar?
It’s like a regular expression for sentences. “Extended Backus-Naur Form.” If you’re familiar, skip ahead. If not…
Here’s a useful slideshow. The wikipedia article is not for the uninitiated, but this article is a bit clearer if you are new to this way of representing grammars. EBNF is from the realm of “Context-Free Grammars” and is mainly used in computing. Given that it is definitely about grammar and syntax, EBNF proves very useful in language analysis and generation. You make rules for breaking down sequences of characters (sentences) into labeled output chunks (parse tree).
Is it possible to parse Japanese with EBNF?
Can we make any real headway using computer syntax to decipher human language? English seems impossible for native language speakers to parse at times. Is it really possible to parse Japanese with EBNF and label parts of speech accurately?
はい! Yes!
Yes! However, for real Japanese from the wild there would need to be many many rules, and any slight deviations from the rules would not result in a full parse. So, rather than try and build our own google translate today, why don’t we just try to cover the maximum amount of Japanese with the minimum amount of rules.
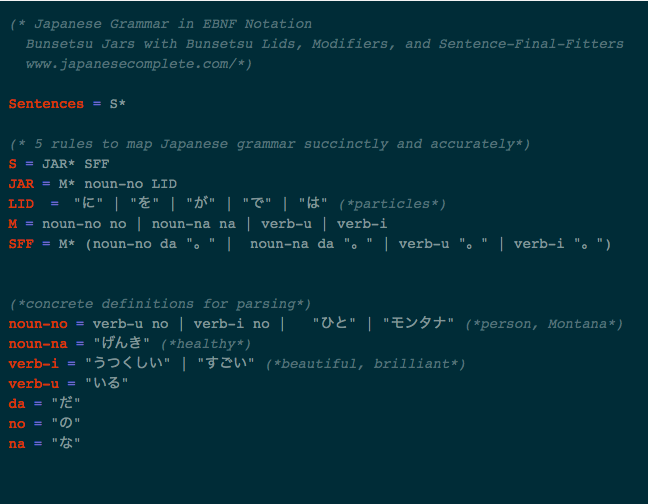
Rules for an EBNF Japanese Grammar
Japanese has nouns, verbs, particles, and sentence-final-fitters. That’s it. * With 5 concepts we can cover the whole Japanese grammar. Amazing. Japanese is regular enough that its composition can be described in a handful of rules.
- A sentence is made of zero or more Bunsetsu-Jars and a Sentence-Final-Fitter.
S = JAR* SFF - A Bunsetsu-Jar is made of zero or more Modifiers, and must have a noun and a particle.
JAR = M* noun-no P | JAR* noun-no no
[UPDATE 2020-1-8: fully recursive with extension of rule 2] - Particles can be any of the Japanese grammar particles that describe the role of their preceding word in a sentence: が、を、と、で、に、etc。
P = が | を | と | で | に … - Sentence-Final-Fitters have only 4 options and can be either nouns with the Copula だ (da), or simply verbs with u, or verbs with i.
SFF = noun-no だ。 | noun-na だ。 | verb-u。 | verb-i。
(sentence-final period included in this rule) - Modifiers can be nouns with their relevant letter (“no” or “na”), or simply verb-u or verb-i.
M = noun-no の | noun-na な | verb-u | verb-i
With just 5 main rules we can parse all of Japanese. That’s exciting! Granted, this is not negation or past tense, just present affirmative, but with small extensions those advancements are accommodatable.
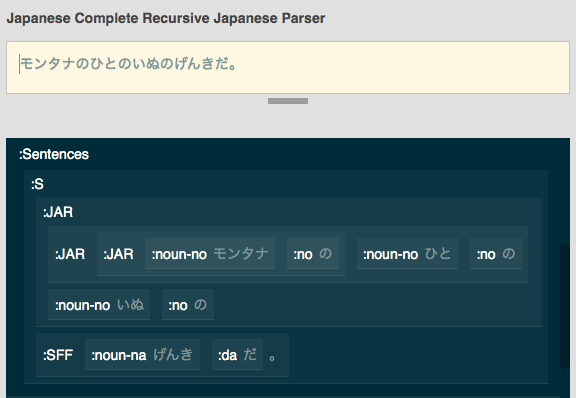
Visuals to Help Expound
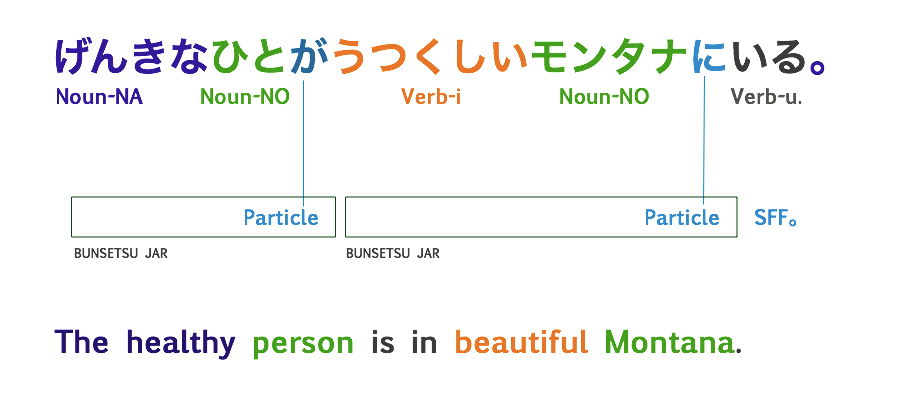
Pictured Above: Any number of Complete Bunsetsu Jars (means a Jar with contents and a Lid = a particle) plus a Sentence-Final-Fitter make a Japanese sentence.
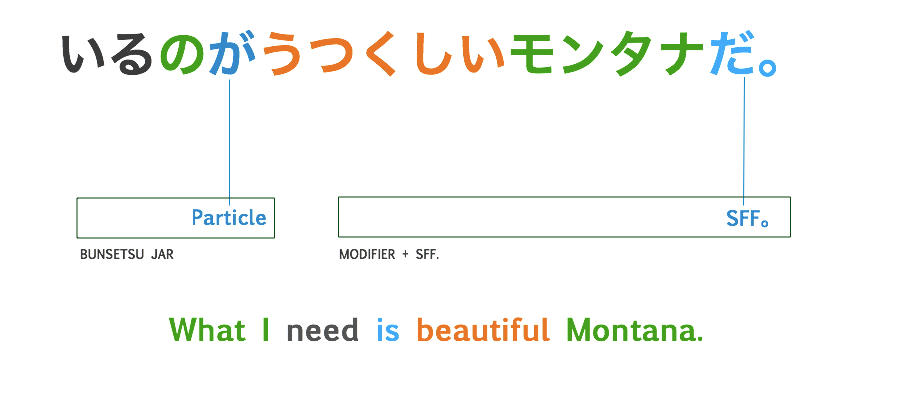



Experimental Data
げんきなひとがうつくしいモンタナにいる。
いるのがうつくしいモンタナだ。
Results from InstaParsing
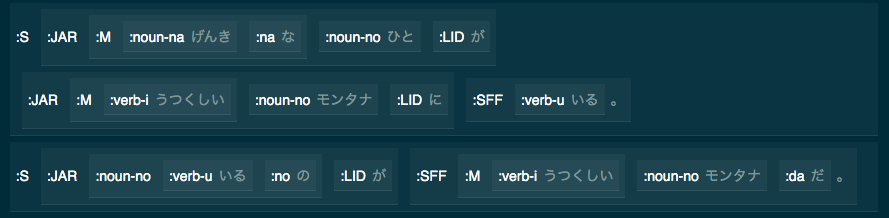
Notice Japanese has no spaces, all parsing relies on accurate detection of symbol in sequence. ImagineifEnglishhadnospaceswoulditbehardtoread?
Recursion Update 2020-1-8
By extending Rule 2 (JAR = … ) to include JAR*, we achieve full recursion on Japanese terms using の [no]
http://instaparse-live.matt.is/#/-Ly63ijYzrhVjVNf7b7a/v1
Death to Adjectives
Japanese has nouns that take な [na] and nouns that take の [no] when they are used as modifiers.
Japanese also has verbs that end with an う [u = oo as in “food”] sound and verbs that end with an い [i = ee as in “week”] sound.
Bringing “adjectives” into the mix just gets things really dirty and offers no benefit to the learner. Stick with 2 kinds of verb and 2 kinds of noun and Japanese will be easy to master.

Parsing Improves Comprehension
Important in language learning are the exercises that parse written language correctly. Learning how the written language is parsed can help one’s mental model, and this will lend to stronger audible comprehension thanks to a deeper understanding of the underlying structure.

Thanks for reading! This breakdown brought to you by Japanese Complete, Rapid Fluency Acquisition Platform.

Related Initiatives
Standard Morphological Analyzer MeCab
Google IME input method super fast lookups with a lossless trie
Tokenizer “Sentencepiece”
Parsing Convo from 2010 on WaniKani Community
Awesome demo of our simplistic parser on Instaparse Live
*When we say “that’s it,” we are putting words like おいしい into the verb-i column, and words like げんきな into the noun-na column. Simplifying into two categories, nouns and verbs, actually proves immensely useful and practical in Japanese. It’s a simplification that should be in all the textbooks and literature. Congrats 2020.

Since you claim that only “small extensions” are required to accommodate the missing language features, do you have an example of the full grammar required to actually parse *all* valid Japanese sentences?
Made the pizzas. Writing a paper on it now.
Hello, I stumbled on your applet or syntax about constructing Japanese sentences and I think it’s just amazing. I used to study programming back in college and now learning Japanese language, and stumbling on your content is (*insert angelic choir ahh sound) like eureka for me. It’s just that to make sense out of the syntax, you just have to know the vocabulary meanings per parse to make it at least somewhat sensibly organic. But this is great stuff. Thanks! 🙂